.jpg?raw=true)
引言
之前看完一些在线优化的论文后一直没有写一些笔记,有一些想法都没有记录下来。最近看完了大佬Shai Shalev-Shwartz写的对在线学习的一篇survey,对之前学的算法有了更清晰的理解(不得不说大佬的文章写的是真的好,算法讲的通俗易懂),就想着写一个专栏来整理出一条自己学习的在线学习算法的路线。
Motivation
学习一个算法,首先要知道这个算法提出的动机是什么,这个算法解决了什么以前的算法没有解决的问题。那么在线学习是为了解决什么问题呢?
同在线学习不同,传统的机器学习模式叫做离线学习。举传统的分类任务为例,我们知道基本的学习流程是这样的:我们首先收集出一个含有大量数据的数据集,然后设计一个模型,参数随机初始化,通过在这个数据集上训练不断更新参数,让模型在数据集上的预测损失越来越小,等到在这个数据集上训练完成之后,最后将这个模型用于分类任务中去。我们可以看到,这个过程是封闭静态的(封闭是指只利用数据集的数据进行训练,静态的是指在训练之后模型就保持不动了)。并且在训练的过程中,我们假设数据集中的数据都是独立同分布的,算法本质上是学习到这个分布。但在实际的情况中,我们现实的环境是多变的,任务中看到的数据未必就是同分布的,我们就希望能利用最新的数据来更新模型,让模型一直在学习,来解决动态环境下的传统机器学习效果不好的问题。这也就将封闭静态的传统学习方式转变为开放动态的在线学习模式。
General Progress
在介绍完在线学习提出的动机之后,接下来将介绍在线学习的基本学习流程。在在线学习中,算法将进行一轮又一轮的学习过程。在第$t$轮的时候,我们将会遇到一个环境给出的问题$x\in\chi$,$\chi$为问题空间,算法给出一个预测的答案$p_t\in D$,$D$为预测空间,然后环境给出正确的答案$y_t$,我们将得到一个损失$l(p_t,y_t)$。总结来说就是如下:

Online Convex Optimization
近年来,许多高效的在线学习算法的设计都受到了凸优化方法的影响。此外,大多数高效算法都可以基于以下的模型进行分析:
 在线学习中许多非凸的难以解决的问题,通过转化为凸问题后利用在线凸优化模型就可以被解决。所以,研究在线凸优化有着十分重要的作用。
在线学习中许多非凸的难以解决的问题,通过转化为凸问题后利用在线凸优化模型就可以被解决。所以,研究在线凸优化有着十分重要的作用。
此外,在在线学习中,根据算法每一轮所获得的信息大小,算法可以主要被分为全信息反馈的在线学习(也就是一般的在线学习问题)和半信息反馈的在线学习(又叫多臂老虎机问题)。在全信息的在线学习中,我们在预测过后,会的到$f_t$的信息,并可以计算出损失$f_t(\pmb{w_t})$的值,但是在半信息的在线学习中,我们只能得到损失$f_t(\pmb{w_t})$的值,而无法获得损失函数的梯度信息。
Regret And Adaptive-Regret
为了衡量在线算法的效果,需要设计出一个指标。还是用以前的损失之和来作为指标吗?但是在不同的实际情况下,损失大也未必就代表算法不好,同一个算法在面对不同的任务时,也可能一个的损失之和特别大,而另一个的损失特别小,我们希望设计一个能够普遍意义上衡量算法好坏的指标,于是,我们在算法得到损失之和后面减去普遍意义上最好的选择所得到的损失之和,得到Regret这一指标。西瓜书393页侧边栏对Regret的描述是这样的,Regret是指在不确定性条件下的决策与确定性条件下的决策所获得的奖赏之间的差别。Regret可以用数学表示为:
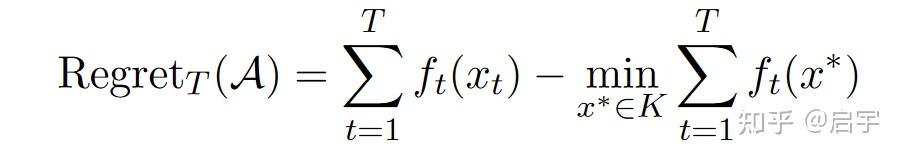 其中$K$是定义域。
其中$K$是定义域。
但是,这样的设计其实也有很大的弊端。就是,在许多多变环境的情况中,无法找到一个 x∗ 使得损失和很小,从而即使算法的Regret很小,在实际情况中也无法获得比较小的损失和,效果也不好。于是,我们需要设计一个动态的指标。于是,Adaptive-Regret这一新的指标被提出。这一指标利用了一个动态的区间更好地反映了算法的效果。Adaptive-Regret的数学表示如下:
Application
随着在线学习的发展,越来越多的算法被用于多变环境下的学习任务中,像无人驾驶,智慧城市,金融分析等领域。
结尾
这篇文章简单介绍了在线学习的基本。下一篇将从直观上的Follow-The-Leader算法到Follow-The-Regularized-Leader算法,并给出Regret Bound。